
Beaucoup de sites laissent Google crawler et indexer des pages sans aucune valeur SEO, faute de bien maîtriser les directives nofollow et noindex. Ces deux balises répondent à des besoins très différents. On vous explique lesquels, avec des méthodes concrètes à appliquer dès aujourd'hui.
Le noindex et le nofollow : deux directives qui ne font pas la même chose
Noindex est une directive de la balise meta robots, tandis que nofollow peut être utilisé soit dans la balise meta robots, soit comme attribut de lien (rel="nofollow"), et ils agissent à des niveaux très différents. Confondre les deux revient à fermer la porte d'une pièce alors qu'on voulait simplement éteindre la lumière.
Le noindex indique aux moteurs de recherche de ne pas indexer une page web. Googlebot la visite, lit son contenu, puis l'exclut des résultats de recherche. La page existe toujours sur votre site web, vos visiteurs y accèdent sans problème, mais elle n'apparaît plus dans Google. C'est la directive utilisée quand vous voulez empêcher l'indexation d'une page spécifique sans la supprimer.
Le nofollow, en revanche, sert à indiquer aux moteurs de recherche de ne pas tenir compte de certains liens : il peut s’appliquer à tous les liens d’une page via la balise meta robots, ou lien par lien via l’attribut rel="nofollow". Cet attribut indique en principe aux robots de ne pas tenir compte de ces liens et de ne pas transmettre de jus SEO vers les pages de destination, même si certains moteurs peuvent parfois les suivre pour découvrir des URL.
À l’opposé, un lien sans attribut nofollow (souvent appelé dofollow en SEO) laisse circuler librement la valeur de lien entre les pages.
Ces deux directives fonctionnent de manière indépendante au sein de la balise meta robots. Vous pouvez très bien utiliser noindex sans nofollow, ou la combinaison des deux selon vos besoins. La confusion entre elles reste pourtant fréquente, et une mauvaise utilisation envoie des signaux contradictoires aux moteurs de recherche, avec un impact direct sur votre référencement naturel.
Quels sont les effets concrets du noindex sur le SEO ?
Ajouter une balise meta robots noindex sur certaines pages web a un effet direct sur la visibilité de votre site dans Google. Bien maîtriser cette directive, c'est choisir précisément ce que le moteur de recherche voit et indexe, tout en orientant progressivement l'exploration vers les contenus à plus forte valeur ajoutée, sans modifier directement le budget de crawl global.
Ce que Google fait quand il rencontre une balise noindex
Quand Googlebot tombe sur un tag noindex dans la section head d'une page, il ne l'ignore pas pour autant. Le robot crawle le contenu de la page, analyse les informations présentes, puis décide simplement de ne pas l'afficher dans ses résultats. La page en noindex disparaît de l'index, mais ses liens internes continuent de transmettre du jus SEO vers le reste du site, sauf si un attribut nofollow les bloque aussi.
Un point de vigilance toutefois : à force de rencontrer cette directive, Google finit par espacer ses visites sur ces pages. La fréquence d'exploration diminue progressivement, ce qui peut réduire la prise en compte effective des liens internes présents sur ces pages dans la durée.
L'impact sur le budget crawl et l'indexation de votre site
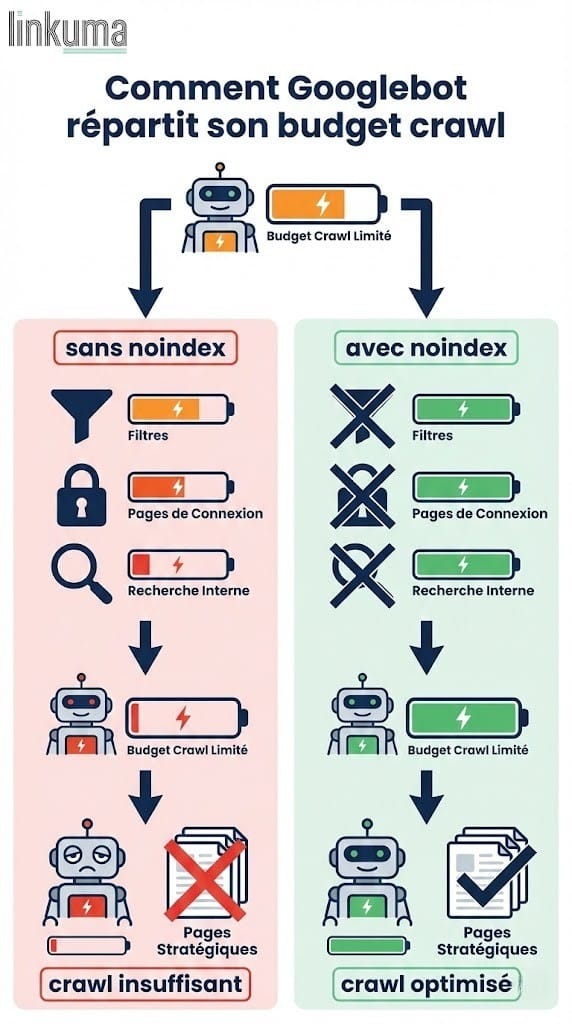
Google alloue à chaque site web un budget de crawl, c’est-à-dire une quantité de ressources d’exploration qu’il consacre au site, limitant le nombre de pages qu’il peut explorer sur une période donnée. Sur un petit blog de 30 pages, la question se pose rarement. Par contre, sur un site e‑commerce ou un portail avec des centaines d’URL, chaque page inutile que Google doit explorer consomme une part de ce budget.
Sans utilisation de noindex sur les contenus de faible qualité, le moteur de recherche gaspille son temps d'exploration sur des pages sans intérêt SEO :
- les pages de résultats de recherche interne
- les filtres et les tris de catégorie produit
- les pages de connexion et d'accès client
- le contenu paginé au-delà de la deuxième page
- les pages de statistiques ou de mentions légales
Ce gaspillage a une conséquence directe : vos pages stratégiques, celles qui ciblent un mot clé précis et génèrent du trafic qualifié, se retrouvent crawlées moins fréquemment.
Si votre site n'apparaît pas sur Google malgré vos efforts d'optimisation, un problème de gestion de l'indexation en est parfois la cause. Un audit via la Google Search Console aide à identifier rapidement ces erreurs et à y remédier.
Comment éviter le contenu dupliqué grâce au noindex ?
Au-delà du budget crawl, le noindex règle un autre problème fréquent : le contenu dupliqué. Beaucoup de sites web génèrent sans le savoir des dizaines de pages au contenu quasi identique, et Google ne sait plus laquelle indexer. Le webmaster n'a rien fait de mal, c'est la structure du site qui crée ces doublons par défaut. Les exemples les plus courants :
- les versions imprimables d'un article
- les pages de tri et de filtre par catégorie
- les archives par date ou par auteur
- les résultats et les avis paginés sur plusieurs URL
- les pages d'accueil accessibles avec et sans "www"
Placer une balise noindex sur ces pages envoie un signal clair au moteur de recherche : cette URL existe bien, les visiteurs la consultent, mais elle ne doit pas être prise en compte dans l'index. C’est une manière simple de gérer la visibilité de certains contenus dupliqués sans les supprimer, même si les balises canonical ou les redirections restent souvent à privilégier.
La balise canonical fonctionne d’ailleurs différemment : elle indique au search engine quelle version d'une page est la référence. Le choix entre les deux dépend de la situation. Si la page dupliquée a une utilité réelle, le noindex la garde en ligne tout en la sortant des résultats. Si deux URL affichent un contenu identique et qu'une seule doit exister aux yeux de Google, la canonical est plus adaptée.
En résumé : canonical quand vous voulez une seule version ”officielle” d’un contenu, noindex quand vous voulez garder la page pour l’usage, mais pas pour le SEO.
Comment implémenter les balises noindex et nofollow ?
Comprendre l'utilité du noindex et du nofollow est un bon début, mais leur mise en œuvre technique doit être irréprochable. Plusieurs méthodes existent, et le choix dépend de votre CMS, de votre accès au code source et de votre niveau technique.
La balise meta robots dans le code HTML
La méthode la plus courante consiste à ajouter une balise meta robots dans la section head de votre page HTML. Voici les trois syntaxes à connaître :
- noindex seul : <meta name="robots" content="noindex">
- nofollow seul : <meta name="robots" content="nofollow">
- la combinaison des deux : <meta name="robots" content="noindex, nofollow">
Cette ligne de code se place entre les balises <head> et </head>, avant le contenu visible de la page. Les moteurs de recherche la lisent en priorité lors de l'exploration.
Pour les fichiers non-HTML (PDF, images, documents), cette méthode ne fonctionne pas. Dans ce cas, le header HTTP X-Robots-Tag prend le relais et envoie la même directive au niveau du serveur. C’est un petit peu plus technique.
Une erreur fréquente par ailleurs : croire que le fichier robots.txt gère le noindex. En réalité, la directive disallow dans le robots txt empêche le crawl d'une URL, mais elle ne désindexe pas une page déjà présente dans Google. Les deux outils ont des fonctions bien distinctes.
La configuration sur WordPress et les autres CMS
Sur WordPress, des extensions dédiées simplifient toute la gestion. Yoast SEO et Rank Math intègrent une option noindex accessible depuis l'éditeur de chaque page ou article. En quelques clics, vous cochez la case et la balise meta robots s'insère automatiquement dans le code source, sans toucher une seule ligne de HTML.
Shopify et PrestaShop proposent des réglages similaires dans leurs paramètres SEO, ou via des modules complémentaires. Le principe est identique : sélectionner les pages concernées, activer la directive, puis vérifier que tout fonctionne.
Cette étape de vérification est trop souvent négligée. Rendez-vous dans Google Search Console, outil "Inspection de l'URL", et testez vos pages une par une. Vous verrez immédiatement si la balise noindex est bien détectée par Googlebot. Cette précaution évite les mauvaises surprises, surtout après une migration ou une refonte de site.
L'accompagnement Linkuma pour une stratégie d'indexation maîtrisée
Bien configurer vos balises noindex et nofollow, c'est déjà un excellent réflexe. Mais une fois vos pages stratégiques correctement indexées, elles ont besoin d'autorité externe pour se positionner face à la concurrence. C'est là qu'un service spécialisé backlink entre en jeu.
Un point à garder en tête : acquérir des backlinks vers une page en noindex ou en nofollow revient à gaspiller du jus SEO. L'autorité récupérée depuis l'extérieur ne se transmet pas en interne si la page cible bloque la circulation des liens. D'où l'intérêt de travailler en parallèle votre stratégie d'indexation et votre profil de backlinks.
L'équipe Linkuma vous accompagne gratuitement et sans engagement sur ces deux volets : audit de votre profil de liens actuel et stratégie de netlinking personnalisée.





